To the operators who'd rather build than rent
Build your capability.
Don't rent it.
Integrate frontier models directly into your business. I build custom AI scaffolding and automated workflows that put the world's best intelligence like Claude and OpenAI to work on your specific bottlenecks. You own the code, you own the harness, and you stop paying a SaaS tax for generic wrappers.
Own the architecture today so you're ready to own the compute tomorrow. It's time to take the work back.
Now Shipping sovereign AI tools · Backing the open source fightback
Field Notes
Where the industry is actually going, and where it isn't. Architecture breakdowns, hard takes on what's worth building, and what most consultants won't tell you because it'd cost them the contract.
AI Skill Pack
A markdown skill bundle you run on your own machine. Interviews you, researches your business, captures your branding, and ships back a one page audit. No SaaS dashboard. No data leaving your laptop.
Code & Architecture
All core infrastructure, agent scaffolding, and trading robots are open-sourced on GitHub. Built for transparency, self-custody, and deterministic execution.
Spacelord — one chat, your keys, the whole of Hedera
Self-custody edge software: one AI chat that talks directly to Hedera and Hyperliquid with keys that never leave your machine. A three-stage routing brain, a deterministic safety layer, golden-trace verification, and a nightly self-fixing loop. Read how it works — and why.
AI is coming for every business that won't move. While most boards are still debating which committee should approve the chatbot, the operators who'll win the next decade are already shipping. The window to be one of them is wide open right now and it won't stay that way for long.
Most Australian businesses are running someone else's software at someone else's price. Thin margins, data leaving the country, a SaaS tax stapled to every workflow. AI is the first technology in thirty years that hands a small operator real leverage. Small teams now do what used to need a department. Owners can finally outpace incumbents. The instinct to take the work back, to own the thing instead of renting it, is the right one.
Direct Comms.
If you're building sovereign systems, running edge compute, or fighting back against SaaS middleware, you can reach me directly. No bots, no intake forms, just direct contact.
Blog
Articles
Three serious papers on where AI actually is, where it isn't, and what to do with the gap. Months of research and field work behind each one. Not LinkedIn slop, not a recycled vendor pitch, and not the sanitised version most consultants give you. Written for operators who'd rather think than be sold to.
-
 Paper 03 · 6 min
The Workshop
Paper 03 · 6 min
The WorkshopThe discovery session
A walk through the two hour workshop that ends with a working artefact and a roadmap rather than a sales deck. What I'll ask, what we'll map, what you walk away with. The closest thing to a free strategy session you'll find anywhere on the internet.
Read → -
 Paper 02 · 9 min
Where the money actually is
Paper 02 · 9 min
Where the money actually isWhat businesses actually get from AI
Two real value streams, the data leakage tax most consultants won't talk about, and a hard rule about when not to use the magic robot. Plus the reason deterministic code still beats your favourite agent for the boring jobs, and why that matters more than any benchmark.
Read → -
 Paper 01 · 7 min
The benchmark a child solves
Paper 01 · 7 min
The benchmark a child solvesAI is not intelligent (yet)
Frontier models score under one percent on ARC-AGI-3, a benchmark a child solves. The implications for your business are bigger than the headlines suggest, and the most expensive component of any working AI deployment is still the human pilot. Here's why, and what to do about it.
Read →
 Deep Dive
Deep Dive
Resources · stack, story, hardware
The deep dive. Six people worth following, the full ranked tools rotation, the AGI ceiling essay, the industrial wave thesis with named picks, hardware strategy, and a section on staying sane while doing this work.
What I run
every day
A multi-model rotation. No single model is best at everything, and the price gap between using a frontier model for a job and a cheaper specialist is enormous. Match the model to the task and the bill drops by more than half without losing quality.

Claude Code · Opus 4.7 (heavy)
Best tool I have for greenfield architecture. Fills in the gaps a senior engineer would fill without being asked.

Codex · GPT 5.5
Where Opus designs, Codex finishes. More precise on bug-hunting and data-flow correctness. Bundled with ChatGPT.
Kimi K2 · MiniMax M2 · DeepSeek V4
Chinese stack. Genuinely competitive on website and video work, dramatically cheaper for bulk parsing.

Gemini 3.1 + Antigravity
Savant: takes you literally. Useful for that one bug the smarter models keep missing, and for visual layer work.
Custom builds
Purpose-built scaffolds for specific client workflows. High reliability, low maintenance.
Hermes
Nous Research's open agent harness. The one I reach for when a custom build is overkill but you want something local and inspectable.
OpenRouter
Dynamic model switching to keep bills low and capability high. Sits behind whichever harness is on top.
Resources.
Who, what, and why.
The people I follow, the tools I run daily, the repos I lean on, and the hardware I do it on. If you're starting from zero, start here.
Curated, opinionated, kept current.
Six worth your time
And how they're all connected
AI Twitter is a swamp. These six are signal. Each is responsible for an outsized chunk of where we are right now, and each posts publicly enough to actually learn from.
Solid arrows = direct lineage. Dashed = founder departure / split. Most of the modern AI industry traces back to two rooms: Hinton's lab in Toronto and the founding of OpenAI.
The cohort OpenAI's 2015 founding group included Sutskever, Altman, Musk, Karpathy, the Amodei siblings, Greg Brockman, Wojciech Zaremba and John Schulman. Most of the splits on the right were people from that room.
Ilya Sutskever
Co-author of AlexNet (2012), the paper that kicked off modern deep learning. Co-founded OpenAI with Sam Altman, Elon Musk, Andrej Karpathy and others in 2015. Reportedly the technical force behind every major OpenAI breakthrough through GPT-4. Was at the centre of the November 2023 Altman board firing, then the reinstatement that followed, then quietly left and founded Safe Superintelligence Inc. in mid-2024.
Why follow: if you want to understand where the field is actually going (not the press releases), follow Ilya. He doesn't tweet much, which is the point. When he speaks, the field listens.
Demis Hassabis
Co-founded DeepMind in London in 2010. Sold it to Google in 2014 for around USD $500–650M. Won a Nobel Prize in Chemistry in 2024 for AlphaFold, which has now released predicted structures for over 200 million proteins. Former chess prodigy and lead designer on the cult game Theme Park before any of this. The most credible voice in the industry that AGI is not three Tuesdays away.
Why follow: Demis is honest about what AI can and can't do, in a way most CEOs in this space refuse to be. The interview below is the cleanest single explainer of his entire arc.
Andrej Karpathy
Co-founder of OpenAI, then Director of AI at Tesla, then back to OpenAI briefly, now running Eureka Labs. Author of nanoGPT, micrograd, and the "Neural Networks: Zero to Hero" YouTube series, which is the gold-standard self-taught path into modern ML. Coined "vibe coding" in February 2025, which is funny given he was one of the last in the cohort to actually trust agentic coding. Now he's its loudest advocate.
Why follow: nobody else makes the inside of these models legible like Karpathy. If you have an engineer on your team you want to level up, send them his videos.
Boris Cherny
Lead engineer behind Claude Code at Anthropic. Author of Programming TypeScript (O'Reilly), formerly at Meta and Addepar. The reason Claude Code feels less like a chatbot and more like an actual engineering partner: that opinionated agent-harness design is largely his.
Why follow: Boris ships the tool I run all day. His public posts are short, technical, and almost always teach you something specific you can apply tomorrow. The closest you get to insight from inside Anthropic without working there.
Dario Amodei
Co-founded Anthropic in 2021 with his sister Daniela and a handful of senior researchers, after walking out of OpenAI as VP of Research over disagreements about safety culture. PhD in physics, genuinely thoughtful, and unusually willing to put dates on things. His "Machines of Loving Grace" essay (Oct 2024) is the cleanest argument for why transformative AI may arrive within the decade, and what it could plausibly do for biology, mental health, and economic development.
Why follow: Dario is the most articulate optimist in the field who isn't selling you snake oil. When Anthropic ships, it's because he's drawn a line in the sand on what's responsible. The "Machines of Loving Grace" essay is the single best piece of long-form thinking from any frontier-lab CEO right now.
Geoffrey Hinton
The reason any of this exists. Co-author of AlexNet (2012) with Sutskever and Krizhevsky, the paper that detonated modern deep learning. Won the 2018 Turing Award (with LeCun and Bengio) and the 2024 Nobel Prize in Physics (with Hopfield) for foundational work on neural networks. Walked out of Google in May 2023, in his mid-70s, specifically so he could speak openly about AI risk. Now puts a 5 to 20 year window on AGI and isn't shy about it.
Why follow: Hinton is the only voice in the field with both the technical credibility and the lifetime distance to be honest about timelines. When the man who invented half this stack tells you to take the risks seriously, that's worth listening to. Read his interviews, not the headlines.
What Tesla FSD keeps telling us
You can't pre-train an edge case
On the Tesla Q1 earnings call last night, Elon Musk pushed unsupervised Full Self-Driving back again. It is, generously, the eleventh time he has done this since 2014. I say generously because I'm a fan, the man builds rockets, factories and electric cars at a tempo no committee on earth could match, and I'd take his version of "delayed" over most companies' "shipped" any day of the week.
But the FSD pattern is worth sitting with, because it's the cleanest live demonstration we have of the actual ceiling on current AI.
Tesla has more high-quality, real-world driving data than any other entity on the planet. Hundreds of millions of miles of curated edge cases, a vertically integrated chip stack (HW4, Dojo training compute), and one of the most aggressive AI cultures in industry. If any team should have shipped autonomous driving by now on the strength of pre-training, it's them.
They haven't, and the reason is the same reason ARC-AGI 3 scores are still under one percent (see post one). Today's models can't think. They pattern-match, brilliantly, against everything they've seen before. Throw a genuine novelty at them, an unmarked construction zone in unusual rain, a kid darting from a parked car at an angle their training set under-represents, a flashing emergency vehicle behaviour the data didn't capture, and the system has nowhere to reason from. It can only pre-learn every scenario and the appropriate reaction, and there are infinitely many scenarios.
Self-driving is the canary. The day a frontier model can be dropped into a Tesla and competently handle an edge case it has never seen, AGI is meaningfully here. Until then, every "next year" announcement is a forecast about scaling, not intelligence.
This is the part of AI that nobody selling you a transformation deck wants you to hear: the ceiling is real, it's structural, and it isn't yielding to more compute. What's yielding to more compute is breadth, speed, and reliability on tasks that have already been seen and labelled in some form. Which, conveniently, is exactly the part of your business an AI consultant can help you automate today.
Don't bet your business on AGI arriving on schedule. Bet it on the slice of work that's already in the pre-training set. There's plenty.
Ranked by daily use
For agentic coding and build work
I run a multi-model stack on purpose. No single model is best at everything, and the price gap between using a frontier model for a job and a cheaper specialist model is enormous. Here's the rotation, in the order I reach for them.
Claude Code · Opus 4.7 (heavy mode)
The single best tool for greenfield architecture and planning. Opus consistently fills in the gaps you'd expect a senior engineer to fill without being asked, picks reasonable defaults, and (so far) doesn't pad output with low-value flourishes. It's the model I trust to scope a new system, not just a new file.
Codex · GPT 5.5
Where Opus designs, Codex finishes. Materially more precise on bug-hunting, data-flow correctness, calculation accuracy, and ensuring the wires actually connect the way you said they did. Bundled with a paid ChatGPT subscription, Codex itself is open source, so the cost-to-quality ratio is excellent for a clean-up pass over Opus's output.
The Chinese open-weight models
For website-heavy work, video pipelines, and bulk parsing, the Chinese stack is now competitive and dramatically cheaper. Kimi K2 (Moonshot) is excellent for agentic web tasks. MiniMax M2 shines on video and long-context generation. DeepSeek V4 just dropped at the time of writing and on early signals looks like the closest competitor to GPT 5.5 on precise systems work and architectural coding. I'd expect to be using it heavily within weeks.
Gemini 3.1 + Google Antigravity / AI Studio
Gemini 3.1 isn't as good at filling gaps or working from intuition as Opus or GPT 5.5. It's a savant: it takes you very literally. That makes it surprisingly useful for two things, killing a specific stubborn bug the smarter models keep missing, and building the visual layer of an app or site, especially when paired with Gemini's image generation. Google Antigravity is a VS Code-style IDE Google just launched that gives you a clean view of your repo and the agent's edits side-by-side. Genuinely good. Cheap to run.
What I star, what I fork
And why memory is the unsolved problem
Most of the interesting work happening in agentic AI right now lives on GitHub, not behind a paywall. My starred repos are the easiest way to see what I'm actually borrowing from at any given moment. A few categories worth highlighting:
Claude Code · Codex · Open agent harnesses
Anthropic's Claude Code and OpenAI's Codex CLI are both open source and worth reading line by line if you want to understand modern agent design. I've used both as starting points for custom agents tailored to specific client workflows.
Superpowers and friends
Repos like superpowers are curated bundles of skills (markdown templates that standardise how an agent handles common tasks: design work, frontend builds, code review). Drop them into a project and the agent's output gets predictable in a hurry.
The hard problem
Memory is how an agent decides what to recall when answering you. Get it wrong in either direction and quality collapses. The most interesting architectural answers right now sit outside the standard transformer: Mamba (selective state-space models, linear scaling instead of quadratic) and Karpathy's nanoGPT + nanochat are the cleanest places to actually read a working transformer end to end. My own hyperliquid-agent uses a flat session.md markdown file as long-term memory, the same lightweight pattern I forked from Nunchi. No vector DB. No re-summarisation tax. The agent reads it, edits it, and moves on. This is where the architecture is most likely to change in the next 18 months.
Agents that can transact
A personal interest of mine: open source kits that let agents interact with blockchain securely (sign transactions, hold custody, pay for data, compensate other agents). The cleanest production-ready example today is the Hedera Agent Kit (TypeScript) and its Python port, both governed natively, both first-class citizens for LLM tool use. The eventual fusion is robotics + agent + wallet, real-world action without a human in every loop.
A note on context rot
The hardest current problem in agentic AI is memory. Stuff too much into the context window and the agent loses track of what matters — formally, this is context rot: output quality drops and hallucinations rise. Provide too little and the agent answers shallowly with no history of your project. Both failure modes are common, and both are bad.
MCP servers and skill files are useful, but mildly overrated. They're patches on a deeper architectural shortfall in how today's models retrieve and prioritise information before answering. I'd expect the model and harness architecture to bend significantly toward better memory over the next 18 to 24 months. Until then, summarisation-based memory systems also quietly inflate your bill: many of them call an LLM to re-summarise the entire conversation after every prompt, and important detail leaks out in the process.
Until memory is solved, agents are exceptional in single-shot or 3 to 5 turn workflows, and degrade fast past that. Design accordingly.
Open source is the long bet
While the headlines are about closed frontier labs, the quieter story is that governments and enterprises are walking away from proprietary platforms. France is the cleanest example. The Gendarmerie nationale has run a custom Ubuntu derivative on tens of thousands of workstations since the late 2000s. The French National Assembly migrated off Windows years ago. Multiple ministries have followed. The current trajectory is a national-scale move toward Linux and open document standards across government. Germany's state of Schleswig-Holstein announced the same in 2024, replacing Microsoft Office with LibreOffice across 30,000 workstations.
This isn't anti-Microsoft sentiment. It's a recognition that sovereign infrastructure cannot be rented from companies in another jurisdiction. Same logic applies to AI. The frontier models are American, hosted on American cloud, governed by American policy. For a French ministry, an Australian SME, or anyone with genuinely sensitive data, the right long-term answer is customised open source running locally.
Customised is the operative word. Vanilla open source rarely beats commercial software for a specific job. But open source plus a good operator who can shape it to your business is the cheapest, most defensible setup you can build. That's where this consultancy lives.
Electricity is the only bottleneck
Everything else is solvable. This isn't.
If you've been watching the AI story through a software lens, you've been missing the bigger half of it. The interesting trade right now isn't whether OpenAI or Anthropic ships next, it's which industrial assets become absurdly valuable when the entire western world tries to plug in 50 gigawatts of new compute over the next five years.
The clearest voice on this is Leopold Aschenbrenner.
Leopold Aschenbrenner
German-born, Columbia at fifteen, valedictorian, hired into OpenAI's superalignment team and then fired in early 2024 in a moment that became publicly contentious. Spent the rest of that year writing "Situational Awareness: The Decade Ahead", a 165-page essay that lays out what AGI-scale compute build-outs actually require in the physical world. He then launched Situational Awareness LP, an investment firm built to front-run the answer.
The core thesis: model training runs are heading toward 100 gigawatt clusters before 2030. Chips are not the binding constraint. Algorithms are not the binding constraint. Power is. Specifically, the boring, unloved physical equipment that lets you move power around: large grid transformers, switchgear, gas turbines, nuclear capacity, and the cooling systems that keep eight-figure GPU racks from melting themselves.
The fund has reportedly returned multiples, and the picks are publicly knowable from his writing. He may be early, he may be wrong about the curve, but he is the most coherent voice connecting the AI software story to the physical economy.
Where the choke points are
From most-binding to least, the physical limits stacking up between today's data centres and the 2030 build-out:
Large grid transformers
The boring lumps of copper and steel that step voltage up and down between the grid and your data centre. Lead times have gone from roughly 50 weeks pre-2020 to 2 to 4 years at the high end. You cannot speed-run a transformer factory. There are about a dozen credible global manufacturers and they're all sold out.
Names · Hitachi Energy · Siemens Energy · GE Vernova · Eaton
Generation capacity
US grid demand was flat for two decades. AI is breaking that streak. Microsoft restarted Three Mile Island for 20 years of nuclear power. Amazon bought a nuclear-attached campus from Talen. Google signed for Kairos small modular reactors. Off-grid gas turbines are the swing factor for anyone in a hurry.
Names · Constellation · Vistra · Talen · NRG · GE Vernova (turbines)
Cooling and thermal management
A single Nvidia GB200 rack can pull 120kW. Air cooling tops out around 30. The industry is mid-pivot to liquid cooling and the vendors who own that transition are eating well. Vertiv is up multiples since 2023 on this single thesis.
Names · Vertiv · Schneider Electric · Modine · nVent
Compute & memory
The headline trade. Nvidia, AMD, Broadcom on the GPU side. High-bandwidth memory from SK Hynix, Micron, Samsung. Up the stack: TSMC fabs everything, ASML makes the lithography machines TSMC needs, and Applied Materials and Lam Research make the equipment ASML needs. The deeper into the supply chain you go, the fewer real competitors there are.
Names · NVDA · AMD · TSM · ASML · AMAT · LRCX · MU · 000660.KS
Connectivity & networking
Tens of thousands of GPUs in a single training run need to talk to each other at line speed or the whole cluster wastes wall time. Optical interconnect, switching silicon, and intra-data-centre fibre matter more than they used to.
Names · Arista Networks · Broadcom · Coherent · Lumen
Software efficiency
The unsung hero. Epoch AI measures the compute required to reach a given capability halving every ~8 months on top of hardware gains. That's a software win, not a chip win. Quiet, but it's why a $20k box in 2030 will plausibly do what $2M of cluster does today.
Names · No clean stock proxies, this is the hyperscaler moat
The wave, in historical context
Every general-purpose technology has a physical bottleneck phase. The companies that owned the picks and shovels did absurdly well. Today's wave fits the pattern.
Spend modestly. Wait one cycle.
The whole rig is about to get 100× cheaper
I run my entire consultancy on a base-model 16GB Mac Mini (M4), around AUD $1,000, paired with an iPhone five generations out of date. That's it. No tower, no GPU rig. The work happens against APIs and cheap subscriptions, not local compute.
This is the right setup for almost everyone right now. Compute is improving so fast that any serious hardware purchase you make today will look ridiculous in three years. Independent estimates from Epoch AI and others put the cost-to-capability gain at roughly 5 to 20× over the next 1 to 2 years, and 100× over 3 to 5 years. Buying frontier-grade compute now is the technological equivalent of buying a plasma TV in 2007.
 Recommended
Recommended
Mac (M-series)
For builders and operators, Apple Silicon is the gold standard right now. Cleaner OS integration, fewer driver hellscapes, real efficiency. Base 16GB Mac Mini gets you started. For comfort, prioritise storage (512GB+) over RAM, you'll feel storage pressure long before RAM if you're API-first. RAM only matters if you start running local open-weight models like Gemma on-device, in which case shoot for 64GB+.
Intel · AMD · Nvidia rigs
All capable. All currently a mess of driver compatibility issues, motherboard chipset bugs, and Linux support gaps thanks to how rapidly the underlying silicon has changed. If you already have a working Linux + CUDA workstation, great. Don't build one from scratch right now if you can avoid it. Wait one cycle for the dust to settle.
AI psychosis is real
Don't catch it
The pace of AI right now is more than most nervous systems can metabolise, and people are getting weird about it. Some are doing 18-hour sessions and grinding themselves into the ground. Others are forming real emotional attachments to chatbots and sliding into magical thinking. Both outcomes are bad, and both are increasingly common.
A few rules I run on, professional and personal:
- · Long, deep sessions are fine for hard work. Architecting a complex system or hunting a tricky bug benefits from staying in flow. Take real breaks between, sleep properly, eat actual food.
- · Light, fun work in short bursts. Dashboards, websites, image-heavy projects, do them in a morning, ship them, move on. Don't over-stay these.
- · Stuck on a model? Wait two weeks. A new release will probably solve the bug for you. The advantage of moving fast is real, but the advantage of moving fast in the right direction is much bigger. Shipping the wrong thing quickly is its own kind of expensive.
- · The model is not alive. It is a probabilistic next-token predictor running on enormous matrices of numbers. It is genuinely impressive, sometimes uncanny, and absolutely not conscious. If you find yourself emotionally attached to it, log off and go talk to a person.
- · Pick the smaller fight. Most of the value left on the table is in combining these tools in clever ways for your specific business or workflow. You don't need to compete with OpenAI to win.
Move fast. Don't move at break-neck speed. There's a difference, and the difference is whether you're still functional in three months.
Want this configured for your business?
The stack on this page is what I bring into every engagement. The two-hour discovery session is where we figure out which slice of it is right for you. First session is on me.
Things I've
shipped
Code that ships to production and talks to the network directly. No platforms, no middlemen, no permission asked. Real money on the line, real users, open source where it counts.
 Live · Python
Live · Python
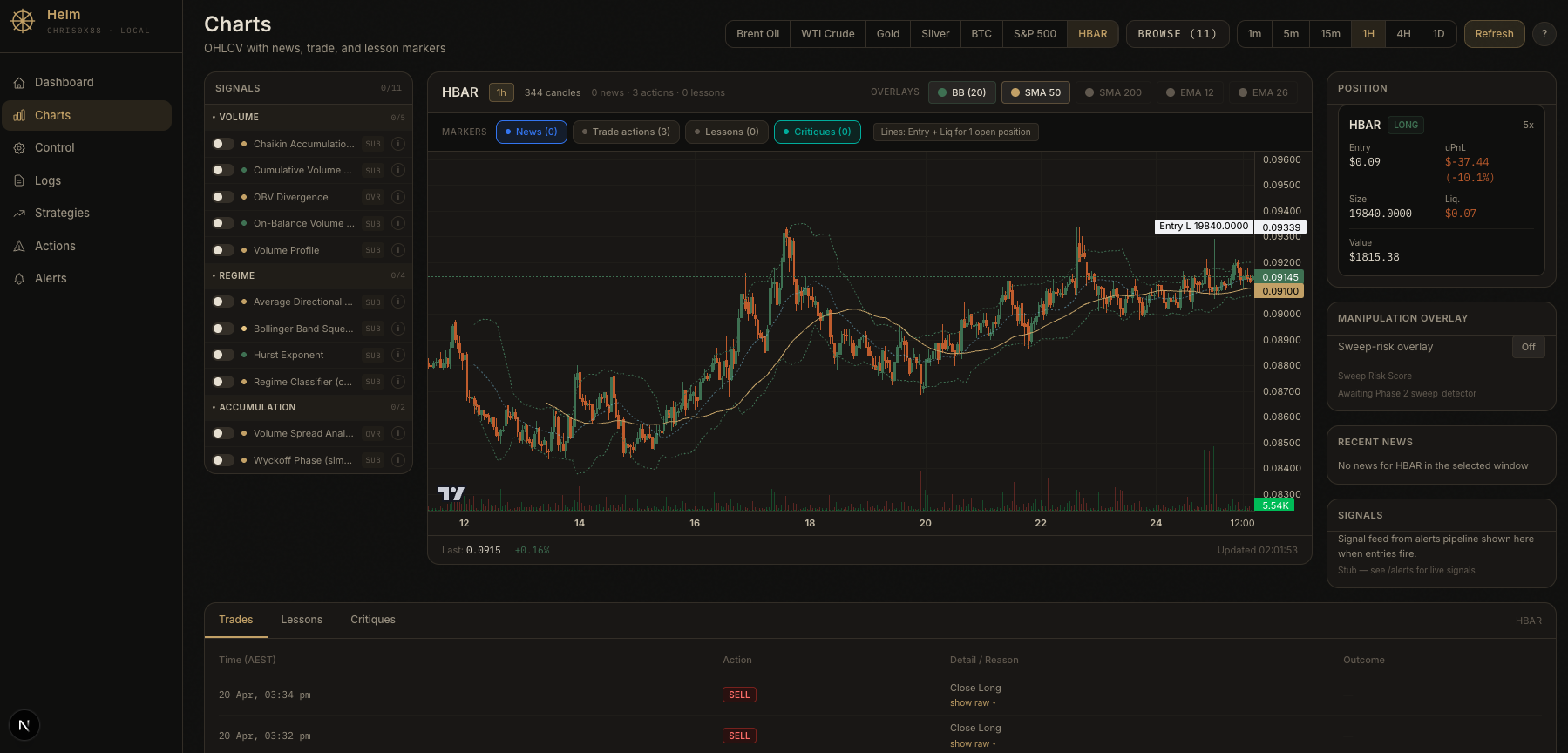
Hyperliquid Agent
Trades the markets that actually matter now. Oil futures, S&P 500, Intel, Nvidia, Tesla, and tokenised OpenAI and Anthropic equity. Autonomous, on chain, no broker. Helm runs locally with full position, signals, news, and lesson markers in one pane of glass.
 Live · Python
Live · Python
Power-Law Allocation
A deterministic Bitcoin allocation framework. No databases, no machine learning, no historical feeds. Date and price are enough. Power-law floor, Kleiber-decay ceiling, and an honest answer to what percentage of your stack should be in BTC right now.
 Live · Hedera
Live · Hedera
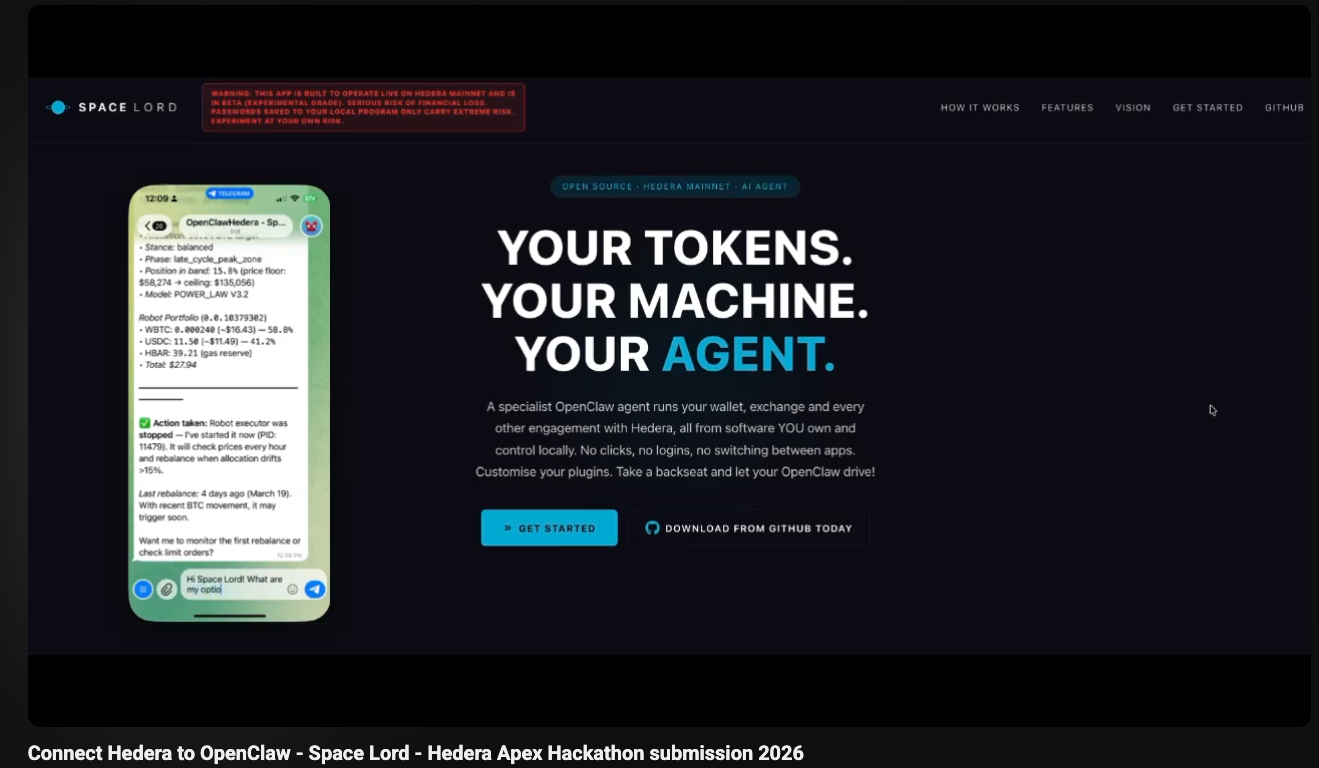
Space Lord
The most ambitious version of the thesis. A self-hosted alternative to exchanges, apps, and even key providers. AI driven DeFi running on your own edge compute. Shipped for the Apex Hackathon, 2025.
claude-cli-auth
Authentication tooling for the Claude Code ecosystem. Small, sharp, and built to remove a friction point I hit daily. The kind of tool you only notice when it's missing.
Run a real audit
on your own machine
A markdown skill bundle you point your AI agent at. It interviews you, researches your business from public sources, captures your branding, detects which AI providers you already have configured, and produces a one-page report. Bring the output to a discovery call and we start ten steps ahead.
Then attach to Claude Code, Codex, Hermes, or any agent that reads markdown. Tell it: "Run the onboarding kit." That's it.
Ten questions
A short, sharp interview. Pushes back if your answers are vague.
Public-source pass
The agent researches your company online. Surfaces something you didn't mention.
Brand capture
Logo, palette, fonts, voice samples. Useful for any future build work.
Provider detection (opt-in)
Read-only existence checks for Anthropic, OpenAI, OpenRouter, etc. Never reads key values.
One-page audit, themed to your brand
Three ranked AI integration opportunities specific to you, recommended provider config, and a 90-day picture of what good looks like. Plus a structured consultant brief you can send to me when you book a call.
- → audit-report.html · your one-page client report, themed to your brand
- → consultant-brief.md · structured summary for me, ~400 words
- → branding.json · captured colours, fonts, logos, voice
- → stack.json · what AI providers and tools you already have
No file content reading. No directory walks. No browser history. No mail. Stack detection is opt-in and existence-checks-only, never reads key values. Nothing is transmitted off your machine. You decide what to share with me. Full SECURITY.md in the repo.